目录
此篇博客大部分内容来自于 , 借此学习 !! (侵删) 主要是上面讲的通俗易懂qwq
本文只是将其用更好的格式进行展现,希望对读者有帮助。
而且以后博客的 markdown 风格会进行改变qwq 主要是找到了新的 typora 用法 2333
不想看那么长的讲解,可以直接先跳到后面的代码再回头看。
定义
对于一个字符串 \(S\) ,它对应的后缀自动机是一个最小的确定有限状态自动机( \(DFA\) ),接受且只接受 \(S\) 的后缀。
比如对于字符串 \(S=\underline{aabbabd}\),它的后缀自动机是
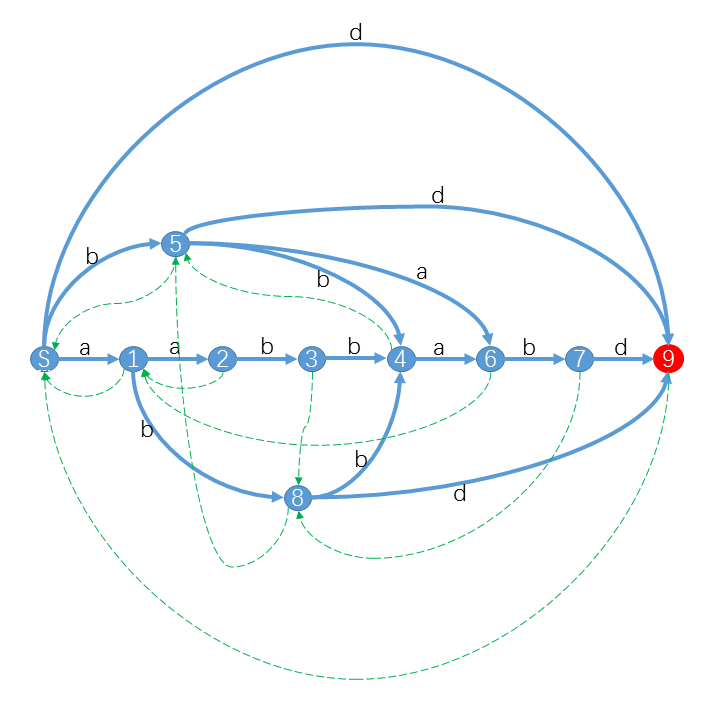
其中 红色状态 是终结状态。你可以发现对于S的后缀,我们都可以从S出发沿着字符标示的路径( 蓝色实线 )转移,最终到达终结状态。
特别的,对于S的子串,最终会到达一个合法状态。而对于其他不是S子串的字符串,最终会“无路可走”。
我们知道 \(SAM\) 本质上是一个 \(DFA\) ,\(DFA\) 可以用一个五元组 <字符集、状态集、转移函数、起始状态、终结状态集> 来表示。至于那些 绿色虚线 虽然不是DFA的一部分,却是SAM的重要部分,有了这些链接 \(SAM\) 是如虎添翼,我们后面再细讲。
其中比较重要的是 状态集 和 转移函数 .
SAM 的状态集
首先我们先介绍一个概念 子串的结束位置 集合 \(endpos\) 。
对于 \(S\) 的一个子串 \(s\) ,\(endpos(s) = s\) 在 \(S\) 中所有出现的结束位置集合。
还是以 \(S=\underline{aabbabd}\) 为例,\(endpos(\underline{ab}) = \{3, 6\}\) ,因为 \(\underline{ab}\) 一共出现了 \(2\) 次,结束位置分别是 \(3\) 和 \(6\) 。同理 \(endpos(\underline{a}) = \{1, 2, 5\}\) , \(endpos(\underline{abba}) = \{5\}\) 。
我们把 \(S\) 的所有子串的 \(endpos\) 都求出来。如果两个子串的 \(endpos\) 相等,就把这两个子串归为一类。最终这些 \(endpos\) 的等价类就构成的 \(SAM\) 的状态集合。
一些性质
令 \(s_1,s_2\) 为 \(S\) 的两个子串 ,不妨设 \(|s_1|\le|s_2|\) (我们用 \(|s|\) 表示 \(s\) 的长度 ,此处等价于 \(s_1\) 不长于 \(s_2\) )。则 \(s_1\) 是 \(s_2\) 的后缀当且仅当 \(endpos(s_1) \supseteq endpos(s_2)\) ,\(s_1\) 不是 \(s_2\) 的后缀当且仅当 \(endpos(s_1) \cap endpos(s_2) = \emptyset\) 。
这个证明是很显然的 :
首先证明 \(s_1\) 是 \(s_2\) 的后缀 \(\Rightarrow\) \(endpos(s_1) \supseteq endpos(s_2)\) 。
因为每次出现 \(s_2\) 时候,\(s_1\) 一定会伴随出现。然后证明 \(endpos(s_1) \supseteq endpos(s_2)\) \(\Rightarrow\) \(s_1\) 是 \(s_2\) 的后缀 。显然 \(endpos(s_2) \not = \emptyset\) ,那么意味着每次 \(s_2\) 结束的时候 \(s_1\) 也会结束,且 \(|s_1| \le |s_2|\) ,那么显然成立。
所以这两个互为充要条件。那么 \(s_1\) 不是 \(s_2\) 的后缀当且仅当 \(endpos(s_1) \cap endpos(s_2) = \emptyset\) 就是其中的推论了,后者是前者的必要条件。
\(SAM\) 中的一个状态包含的子串都具有相同的 \(endpos\),它们都互为后缀。
其中一个状态指的是从起点开始到这个点的所有路径组成的子串的集合。
例如上图中状态 \(4\) 为 \(\{\underline{bb},\underline{abb},\underline{aabb}\}\) 。
我们用 \(substrings(st)\) 表示状态 \(st\) 中包含的所有子串的集合,\(longest(st)\) 表示 \(st\) 包含的最长的子串,\(shortest(st)\)表示\(st\)包含的最短的子串。
例如对于状态 \(7\) ,\(substring(7)=\{\underline{aabbab},\underline{abbab},\underline{bbab},\underline{bab}\}\),\(longest(7)=\underline{aabbab}\),\(shortest(7)=\underline{bab}\) 。
那么有 对于一个状态 \(st\) ,以及任意 \(s\in substrings(st)\) ,都有 \(s\) 是 \(longest(st)\) 的后缀。
证明比较容易,因为 \(endpos(s)=endpos(longest(st)) ~|s| \le |st|\) ,所以 \(endpos(s) ⊇ endpos(longest(st))\) ,根据我们刚才证明的结论有 \(s\) 是 \(longest(st)\) 的后缀。
对于一个状态 \(st\) ,以及任意的 \(longest(st)\) 的后缀 \(s\) ,如果 \(s\) 的长度满足:\(|shortest(st)| \le |s| \le |longsest(st)|\) ,那么 \(s \in substrings(st)\) 。
其实是定义然后很显然?证明有:\(|shortest(st)| \le|s|\le|longsest(st)|\)> ,所以\(endpos(shortest(st)) \supseteq endpos(s) \supseteq endpos(longest(st))\) ,又 \(endpos(shortest(st))=endpos(longest(st))\) 所以 \(endpos(shortest(st)) = endpos(s) = endpos(longest(st))\) ,所以 \(s\in substrings(st)\) 。
也就是说 \(substrings(st)\) 包含的是 \(longest(st)\) 的一系列 连续 后缀。
例如 状态 \(7\) 中包含的就是 \(\underline{aabbab}\) 的长度分别是 \(6,5,4,3\) 的后缀;状态 \(6\) 包含的是 \(\underline{aabba}\) 的长度分别是 \(5,4,3,2\) 的后缀。
SAM 的后缀链接
前面我们讲到 \(substrings(st)\) 包含的是 \(longest(st)\) 的一系列 连续 后缀。这连续的后缀在某个地方会“断掉”。
比如状态 \(7\) ,包含的子串依次是 \(\underline{aabbab},\underline{abbab},\underline{bbab},\underline{bab}\) 。按照连续的规律下一个子串应该是 \(\underline{ab}\) ,但是 \(\underline{ab}\) 没在状态 \(7\) 里。
这是为什么呢?
\(\underline{aabbab},\underline{abbab},\underline{bbab},\underline{bab}\) 的 \(endpos\) 都是 \(\{6\}\) ,下一个 \(\underline{ab}\) 当然也在结束位置 \(6\) 出现过,但是 \(\underline{ab}\) 还在结束位置 \(3\) 出现过,所以 \(\underline{ab}\) 比 \(\underline{aabbab},\underline{abbab},\underline{bbab},\underline{bab}\) 出现次数更多,于是就被分配到一个新的状态中了。
当 \(longest(st)\) 的某个后缀 \(s\) 在新的位置出现时,就会“断掉”,\(s\) 会属于新的状态。
比如上例中 \(\underline{ab}\) 就属于状态 \(8\) ,\(endpos(\underline{ab})=\{3,6\}\) 。当我们进一步考虑 \(\underline{ab}\) 的下一个后缀 \(\underline{b}\) 时,也会遇到相同的情况:\(\underline{b}\) 还在新的位置 \(4\) 出现过,所以 \(endpos(\underline{b})=\{3,4,6\}\) ,\(\underline{b}\) 属于状态 \(5\) 。在接下去处理 \(\underline{b}\) 的后缀我们会遇到空串, \(endpos(\underline{})= \{0,1,2,3,4,5,6\}\) ,状态是起始状态 \(S\) 。
于是我们可以发现一条状态序列: \(7 \to 8 \to 5 \to S\) 。这个序列的意义是 \(longest(7)\) 即 \(\underline{aabbab}\) 的后缀依次在状态 \(7,8,5,S\) 中。我们用后缀链接 \(Suffix Link\) 这一串状态链接起来,这条 \(link\) 就是上图中的绿色虚线。
后面这个会有妙用qwq
SAM 的转移函数
最后我们来介绍 \(SAM\) 的转移函数。对于一个状态 \(st\) ,我们首先找到从它开始下一个遇到的字符可能是哪些。我们将 \(st\) 遇到的下一个字符集合记作 \(next(st)\) ,有 \(next(st) = \{S[i+1] | i \in endpos(st)\}\) 。例如 \(next(S)=\{S[1], S[2], S[3], S[4], S[5], S[6], S[7]\}=\{a, b, d\}\) ,\(next(8)=\{S[4], S[7]\}=\{b, d\}\) 。
一些性质
对于一个状态 \(st\) 来说和一个 \(next(st)\) 中的字符 \(c\) ,你会发现 \(substrings(st)\) 中的所有子串后面接上一个字符 \(c\) 之后,新的子串仍然都属于同一个状态。
比如对于状态 \(4\) ,\(next(4)=\{a\}\) ,\(\underline{aabb},\underline{abb},\underline{bb}\) 后面接上字符 \(\underline{a}\) 得到 \(\underline{aabba},\underline{abba},\underline{bba}\) ,这些子串都属于状态 \(6\) 。
所以我们对于一个状态 \(st\) 和一个字符 \(c\in next(st)\) ,可以定义转移函数 \(trans(st, c) = \{x | longest(st) + c \in substrings(x) \}\) 。换句话说,我们在 \(longest(st)\)(随便哪个子串都会得到相同的结果)后面接上一个字符 \(c\) 得到一个新的子串 \(s\) ,找到包含 \(s\) 的状态 \(x\) ,那么 \(trans(st, c)\) 就等于\(x\) 。
算法构造
构造方法
\(SAM\) 有 \(O(|S|)\) 的构造方法,接下来我们讲讲如何构造。
首先为了实现 \(O(|S|)\) 的构造,对于每个状态肯定不能保存太多数据。例如 \(substrings(st)\) 肯定无法保存下来了。
对于状态 \(st\) 我们只保存如下数据:
| 数据 | 含义 |
|---|---|
| \(maxlen[st]\) | \(st\) 包含的最长子串的长度 |
| \(minlen[st]\) | \(st\) 包含的最短子串的长度 |
| \(trans[st][1..c]\) | \(st\) 的转移函数, \(c\) 为字符集大小 |
| \(link[st]\) | \(st\) 的后缀链接 |
其次,我们使用增量法构造 \(SAM\) 。我们从初始状态开始,每次考虑添加一个字符 \(S[1],S[2],...,S[N]\) ,依次构造可以识别 \(S[1], S[1..2], S[1..3], \cdots ,S[1..N]=S\) 的 \(SAM\) 。
假设我们已经构造好了 \(S[1..i]\) 的 \(SAM\) 。这时我们要添加字符 \(S[i+1]\) ,于是我们新增了 \(i+1\) 个 \(S[i+1]\) 的后缀要识别:\(S[1..i+1], S[2..i+1], ... S[i..i+1], S[i+1]\) 。 考虑到这些新增状态分别是从 \(S[1..i], S[2..i], S[3..i], \cdots , S[i], \underline{}\) (空串)通过字符 \(S[i+1]\) 转移过来的,所以我们还要对 \(S[1..i], S[2..i], S[3..i], \cdots , S[i], \underline{}\) (空串) 对应的状态们增加相应的转移。
我们假设 \(S[1..i]\) 对应的状态是 \(u\) ,等价于 \(S[1..i]\in substrings(u)\) 。根据上面的讨论我们知道 \(S[1..i], S[2..i], S[3..i], ... , S[i], \underline{}\) (空串)对应的状态们恰好就是从 \(u\) 到初始状态 \(S\) 的由 \(Suffix Link\) 连接起来路径上的所有状态,不妨称这条路径(上所有状态集合)是 \(suffix-path(u\to S)\) 。
这个也就是说,对于 \(S[1..i] = longest(u) \in substrings(u)\) 对于其他 \(s'\) 为 \(longest(u)\) 的后缀 要么存在于 \(u\) 这个状态中,要么存在于前面的 \(SuffixLink\) 连接的状态中。
显然至少 \(S[1..i+1]\) 这个子串不能被以前的 \(SAM\) 识别,所以我们至少需要添加一个状态 \(z\) ,\(z\) 至少包含\(S[1..i+1]\) 这个子串。
首先考虑一种最简单的情况:对于 \(suffix-path(u \to S)\) 的任意状态 \(v\) ,都有 \(trans[v][S[i+1]]=NULL\) 。这时我们只要令 \(trans[v][S[i+1]]=z\) ,并且令 \(link[st]=S\) 即可。
例如我们已经得到了 \(\underline{aa}\) 的 \(SAM\) ,现在希望构造 \(\underline{aab}\) 的 \(SAM\) 。就如下图所示:
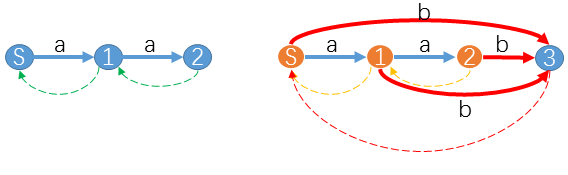
此时 \(u=2,z=3\) , \(suffix-path(u\to S)\) 是 桔色状态 组成的路径 \(2-1-S\) 。并且这 \(3\) 个状态都没有对应字符 \(b\) 的转移。所以我们只要添加红色转移 \(trans[2][b]=trans[1][b]=trans[S][b]=z\) 即可。当然也不要忘了 \(link[3]=S\) 。
还有一种难一点的情况为:\(suffix-path(u\to S)\) 上有一个节点 \(v\) ,使得 \(trans[v][S[i+1]]\not =NULL\) 。
我们以下图为例,假设我们已经构造 \(\underline{aabb}\) 的 \(SAM\) 如图,现在我们要增加一个字符 \(a\) 构造 \(\underline{aabba}\) 的 \(SAM\) 。
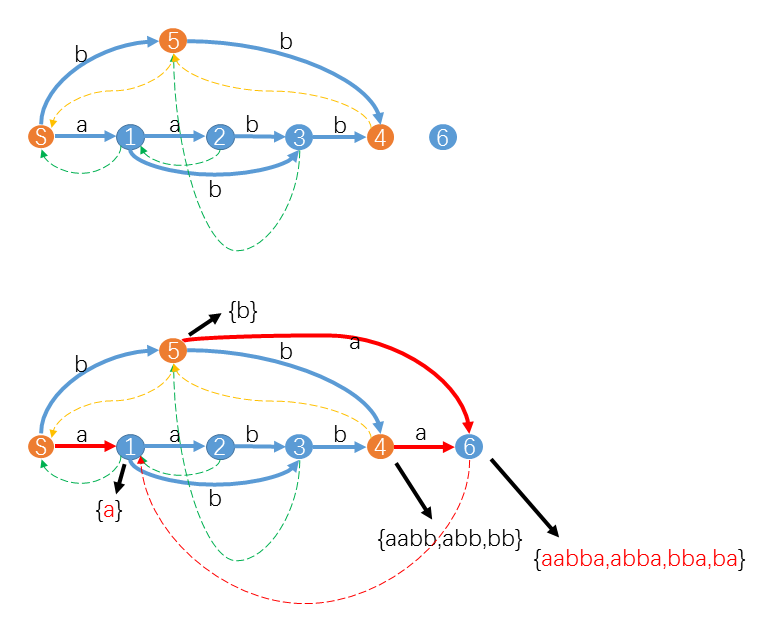
这时 \(u=4,z=6,suffix-path(u\to S)\) 是 桔色状态 组成的路径 \(4-5-S\) 。对于状态 \(4\) 和状态 \(5\) ,由于它们都没有对应字符 \(a\) 的转移,所以我们只要添加红色转移\(trans[4][a]=trans[5][a]=z=6\) 即可。但此时 \(trans[S][a]=1\) 已经存在了。
不失一般性,我们可以认为在 \(suffix-path(u\to S)\) 遇到的第一个状态 \(v\) 满足 \(trans[v][S[i+1]]=x\) 。这时我们需要讨论 \(x\) 包含的子串的情况。
如果 \(x\) 中包含的最长子串就是 \(v\) 中包含的最长子串接上字符\(S[i+1]\) ,等价于 \(maxlen(v)+1=maxlen(x)\) 。这种情况比较简单,我们只要增加 \(link[z]=x\) 即可。
比如在上面的例子里,\(v=S, x=1\) ,\(longest(v)\) 是空串,\(longest(1)=\underline{a}\) 就是 \(longest(v)+\underline{a}\) 。
我们将状态 \(6\) \(link\) 到状态 \(1\) 就行了。因为此时 \(z\) 只缺少了这个 \(suffix-path(x \to S)\) 的状态。
如果 \(x\) 中包含的最长子串 不是 \(v\) 中包含的最长子串接上字符 \(S[i+1]\) ,等价于 \(maxlen(v)+1 < maxlen(x)\) ,这种情况最为复杂。
不失一般性,我们用下图表示这种情况,这时增加的字符是 \(c\) ,状态是 \(z\) 。

在 \(suffix-path(u\to S)\) 这条路径上,从 \(u\) 开始有一部分连续的状态满足 \(trans[u..][c]=NULL\) ,对于这部分状态我们只需增加 \(trans[u..][c]=z\) 。紧接着有一部分连续的状态 \(v..w\) 满足\(trans[v..w][c]=x\) ,并且 \(longest(v)+c\) 不等于 \(longest(x)\) 。
这时我们需要从 \(x\) 拆分出新的状态 \(y\) ,并且把原来 \(x\) 中长度小于等于 \(longest(v)+c\) 的子串分给 \(y\) ,其余子串留给 \(x\) 。同时令 \(trans[v..w][c]=y\) ,\(link[y]=link[x], ~link[x]=link[z]=y\) 。
也就是 \(y\) 先继承 \(x\) 的 \(link\) ,并且 \(x,z\) 前面断开的 \(substrings\) 就存在于 \(y\) 中了。
好像比较复杂。我们来举个例子。假设我们已经构造 \(\underline{aab}\) 的 \(SAM\) 如图,现在我们要增加一个字符\(b\) 构造 \(\underline{aabb}\) 的 \(SAM\) 。
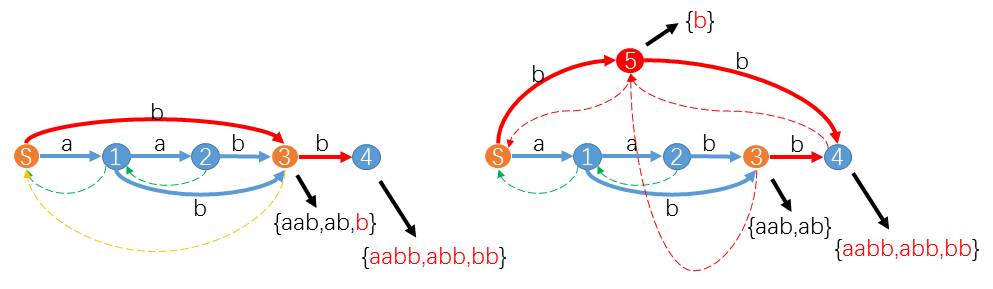
当我们处理在 \(suffix-path(u\to S)\) 上的状态 \(S\) 时,遇到 \(trans[S][b]=3\) 。并且 \(longest(3)=\underline{aab}\) ,\(longest(S)+ \underline{b}= \underline{b}\) ,两者不相等。其实不相等意味增加了新字符后 \(endpos(\underline{aab})\) 已经不等于 \(endpos(\underline{b})\) ,势必这两个子串不能同属一个状态 \(3\) 。这时我们就要从 \(3\) 中新拆分出一个状态 \(5\) ,把 \(\underline{b}\) 及其后缀分给 \(5\) ,其余的子串留给 \(3\) 。同时令 \(trans[S][c]=5, link[5]=link[3]=S, link[3]=link[6]=5\) 。
到此整个构造算法全部结束。
时间复杂度证明
不难发现这个的时间复杂度只与 状态以及转移的数量 有关。
我们考虑分析这两个部分。这部分证明来自大佬 。
状态的数量
由长度为 \(n\) 的字符串 \(s\) 建立的后缀自动机的状态个数不超过 \(2n-1\)(对于 \(n\ge 3\) )。
证明:上面描述的算法证明了这一性质(最初自动机包含一个初始节点,第一步和第二步都会添加一个状态,余下的 \(n-2\) 步每步由于需要分割,至多增加两个状态)。
所以就是 \(1+2+(n-2) \times 2 = 2n-1\) 了。
有趣的是,这一上限无法被改善,即存在达到这一上限的例子: \(\underline{abbb...}\) 。每次添加都需要分割。
转移的数量
由长度为 \(n\) 的字符串 \(s\) 建立的后缀自动机中,转移的数量不超过 \(3n-4\) (对于 \(n\ge 3\) )。
证明: 我们计算 连续的 转移个数。考虑以 \(S\) 为初始节点的自动机的最长路径树。这棵树将包含所有连续的转移,树的边数比结点个数小 \(1\) ,这意味着连续的转移个数不超过 \(2n-2\) 。
我们再来计算 不连续 的转移个数。考虑每个不连续转移;假设该转移——转移 \((p,q)\) ,标记为 \(c\) 。对自动机运行一个合适的字符串 \(u+c+w\) ,其中字符串 \(u\) 表示从初始状态到 \(p\) 经过的最长路径,\(w\) 表示从 \(q\) 到任意终止节点经过的最长路径。
一方面,对所有不连续转移,字符串 \(u+c+w\) 都是不同的(因为字符串 \(u\) 和 \(w\) 仅包含连续转移)。另一方面,每个这样的字符串 \(u+c+w\) ,由于在终止状态结束,它必然是完整串 \(s\) 的一个后缀。由于 \(s\) 的非空后缀仅有 \(n\) 个,并且完整串 \(s\) 不能是某个 \(u+c+w\) (因为完整串 \(s\) 匹配一条包含 \(n\) 个连续转移的路径),那么不连续转移的总共个数不超过 \(n-1\) 。
有趣的是,仍然存在达到转移个数上限的数据:\(\underline{abbb...bbbc}\) 。
这个证明其实我是没太懂的。。记下结论吧。
代码实现
我们令 \(id\) 为这次插入字符的编号,\(trans,maxlen,link\) 意义同上。\(Last\) 为上次最后插入的状态的编号,\(Size\) 为当前的状态总数,\(clone\) 为复制节点即上文的 \(y\) 。 具体来说如下代码所示:
\(minlen\) 可以最后计算 ,因为我们是从 \(link\) 处断开的,所以显然有 \(minlen[i] = maxlen[link[i]]+1\) 。
struct Suffix_Automata { int maxlen[Maxn], trans[Maxn][26], link[Maxn], Size, Last; Suffix_Automata() { Size = Last = 1; } inline void Extend(int id) { int cur = (++ Size), p; maxlen[cur] = maxlen[Last] + 1; for (p = Last; p && !trans[p][id]; p = link[p]) trans[p][id] = cur; if (!p) link[cur] = 1; else { int q = trans[p][id]; if (maxlen[q] == maxlen[p] + 1) link[cur] = q; else { int clone = (++ Size); maxlen[clone] = maxlen[p] + 1; Cpy(trans[clone], trans[q]); link[clone] = link[q]; for (; p && trans[p][id] == q; p = link[p]) trans[p][id] = clone; link[cur] = link[q] = clone; } } Last = cur; }} T; 实际应用
其实这个可以用后缀数组做,具体来说,答案就是 \(\displaystyle \sum_{i=1} ^ n (n - sa[i] + 1) - height[i]\) 。我们考虑 \(sa\) 相邻两个后缀。首先多出了 \((n - sa[i] + 1)\) 个后缀,然后 \(LCP\) 长度为 \(height[i]\) 的子串重复计算过,减去就行了。
用 \(SAM\) 的话,其实就是统计所有状态包含的子串总数,也就是 \(\displaystyle \sum_{i=1}^{Size} maxlen[i] - minlen[i]+1\) ,建完直接算就行了。注意前面讲过的 \(minlen[i] = maxlen[link[i]]+1\) 。
我们首先考虑一个子串出现的次数,不难发现就是它 \(endpos\) 集合的大小。所以我们当前需要计算的就是 \(\forall st, |endpos(st)|\) 的大小。如果我们每次构建时候维护这个的话,每次需要跳完整个 \(suffix-path(u\to S)\) ,对于这上面的所有节点加一(这是因为后缀路径上的所有点都具有新加状态的 \(endpos\) ,总时间复杂度能达到 \(O(|S|^2)\) ,但是对于随机数据表现优秀)。我们先构造完 \(SAM\) 最后再算答案。我们单独把它所有的后缀路径拿出来看一下是什么情况。
我们以最开始的 \(SAM\) 为例,它后缀链接构成的图如下:
不难他的后缀链接组成了一个 \(DAG\) 图。并且它反向建那么就是一颗以 \(S\) 为根的树(因为除了 \(S\) 每个点有且仅有一个出边,并且不可能存在环,因为 \(maxlen[link[i]] < maxlen[i]\) ),我们称之为后缀树。

前面讲过了我们每次是暴力把路径上的所有点权值 \(+1\) 。我们就能转化成 \(DAG\) 每一个点对于它能走的路径上的所有点 \(+1\) ,这个直接考虑在 \(DAG\) 图上进行拓扑 \(dp\) 就行了。
但注意 \(clone\) 的节点是不能对它到 \(S\) 的路径上有单独贡献的,因为它的贡献会在它的本体上计算一遍。
然后这题是要计算对于所有 \(i\) 长度为 \(i\) 子串个数,那么不难发现一个状态 \(st\) 包含的是长度为 \([minlen(st), maxlen(st)]\) 的子串,那么它对于 \(minlen(st) \le k \le maxlen(st)\) 的长度的答案具有贡献。这个我们打个区间取 \(max\) 就行了。这样要写一个线段树比较麻烦,但我们发现对于长度更大 \(ans\) 我当前肯定也是可以使用的,一开始把标记打在 \(maxlen\) 上,直接最后倒着取 \(max\) 就行了。
至此这道题就做完啦。复杂度为 \(O(n)\) 比排序 \(len\) 的复杂度 \(O(n \log n)\) 要优秀。
vector G[Maxn]; int indeg[Maxn];void Build() { For (i, 1, Size) G[i].push_back(link[i]), ++ indeg[link[i]];}void Topo() { queue Q; Build(); For (i, 0, Size) if (!indeg[i]) Q.push(i); while (!Q.empty()) { int u = Q.front(); Q.pop(); for (int v : G[u]) { val[v] += val[u]; if (!(-- indeg[v])) Q.push(v); } } For (i, 1, Size) chkmax(Tag[maxlen[i]], val[i]); Fordown (i, n, 1) chkmax(Tag[i], Tag[i + 1]);} 此题就是要统计所有本质不同的子串权值和,对于每个子串权值定义就是它在十进制下的值。因为每个数都是从前往后构成的,并且 \(SAM\) 上每个状态的 \(substrings\) 是从起点开始的路径构成的单词集合。
正向的转移函数 \(trans[u][1..c]\) 是一个 \(DAG\) 图。
因为状态有限,所以不可能存在环使得状态无限。
不难考虑用正向拓扑 \(dp\) 求解这个值。令 \(dp_{i}\) 为状态 \(i\) 所有 \(substrings(i)\) 的权值和,那么显然有 \(\displaystyle dp_{v}=\sum_{trans[u][id]} dp[u] \times 10 + id\) . 但这样显然会错... 因为一个状态可能有很多子串加上了 \(id\) 这个值,但我们只加上了一个,所以我们记下每个状态具有的子串个数 \(tot_i\) 。那么有 \(\displaystyle tot_v = \sum_{trans[u][id]}tot_u\) 。又有 \(\displaystyle dp_v = \sum_{trans[u][id]}dp[u] \times 10 + id \times tot_u\) 。
但是这个是有许多串一起询问答案,可以用 广义后缀自动机 来解决。
但其实这题我们可以用当初做后缀数组题的一些思想,我们对于许多子串在中间加入一些字符例如 \(\underline{:}\) (字符集大小 \(+1\) )将其隔开,然后每次统计的时候不能统计中间具有 \(\underline{:}\) 的字符,对于这些枚举的边为这些转移的,我们就不转移 \(dp,tot\) 就可以了。
int val[Maxn], indeg[Maxn], tot[Maxn], n;void Get_Val() { queue Q; Q.push(1); tot[1] = 1; For (i, 1, Size) For (j, 0, spc) ++ indeg[trans[i][j]]; while (!Q.empty()) { int u = Q.front(); Q.pop(); For (i, 0, spc) { int v = trans[u][i]; if (!v) continue ; if (i != 10) { (tot[v] += tot[u]) %= Mod; (val[v] += val[u] * 10ll % Mod + 1ll * i * tot[u] % Mod) %= Mod; } if (!(-- indeg[v])) Q.push(v); } }} 这个比较巧妙qwq ,首先先讲如何求 两个串的最长公共子串 \((LCS)\) 注意此处不是最长公共前缀 \((LCP)\) 。
假设我们当前有两个串 \(S\) 与 \(T\) ,求它们的 \(LCS\) 我们考虑先把 \(S\) 的 \(SAM\) 建出来。
然后对于 \(T\) 的每一个位置 \(T[i]\) 计算出以 \(T[i]\) 为结尾的子串与 \(S\) 的 \(LCS\) 。
比如对于 \(S=\underline{aabbabd}, T=\underline{abbabb}\) 。得到的情况如下:
S: aabbabdT: abbabb 1: a2: ab3: abb4: abba5: abbab6: abb这个如何求呢?
首先,对于每一个 \(T[i]\) 我们记两个数据 \(u, l\) 分别代表当前 \(LCS\) 所在的 \(SAM\) 状态以及它在原串的长度。
我们假设我们已经得到了 \(T[i-1]\) 的 \(u,l\) ,现在我们要求 \(T[i]\) 的 \(u',l'\) 。讨论几种情况就行了。
\(trans[u][T[i]] =v,v \not = NULL\) 。这种就很显然了,直接向后匹配一位。\(u' = v, l' = l +1\) 。
\(trans[u][T[i]]=NULL\) 。这种我们可以用类似 \(KMP\) 和 \(AC\) 自动机的方法跳 \(fail\) ,此处我们的 \(Suffix~Link\) 相当于 \(fail\) ,因为每次失配后我们只需要找它的一个前缀使得刚好匹配。我们有之前的结论 \(longest(st)\) 的前缀必在 \(Suffix-Path(u \to S)\) 的状态上。
所以我们每次向前跳 \(Suffix-Path(u \to S)\) 上的点 \(q\) ,直到找到第一个 \(trans[q][T[i]] = v, v \not = NULL\) ,此时 \(u'=v, l' = maxlen[q]+1\) 。因为此时 \(maxlen[q]\) 是刚好能满足的前缀的长度。
如果整条链不存在那就令 \(u'=s, l'=0\) 。
这样就是 \(O(|S| + |T|)\) 的复杂度了,轻松愉悦。
有了这个后就很好做了。循环的串,不难想到拆坏为链,也就是说我们将要查询的串倍长去里面匹配。
假设对于 \(\underline{aab}\) 我们将其变成 \(\underline{aabaab}\) 然后对于其中每一个位置,如果与原串得到的 \(LCS\) 的长度不小于这个串的长度 \((l \ge |T|)\) ,那么以这个点结尾的循环串就会在原串中出现。还是刚刚那个例子,假设原串是 \(\underline{abaaa}\) ,对于查询串位置为 \(5\) 的地方与原串 \(LCS\) 长度为 \(4\) 那么对于 \(\underline{baa}\) 必在原串中出现过,它出现的次数也就是求 \(LCS\) 时候状态 \(u\) 出现的次数。
状态出现次数可以用前面讲过的计数方法来求,求 \(LCS\) 的状态也可以按前面来求。但这样有两个问题……
- 有些串会计算多次。例如 \(\underline{a}\) ,将其倍长后为 \(\underline{aa}\) 。我们会计算两次 \(a\) ,此时只要对 \(SAM\) 中被统计的状态打个标记就行了(也就是记一下现在被哪个版本统计过)。
- 有些串不该被算却被计算了。同上 \(\underline{a}\) 倍长后为 \(\underline{aa}\) ,我们会把 \(\underline{aa}\) 也计算进来,这样显然是不行的。所以我们每次得到了一个 \(LCS\) 后如果长度 \(l \ge |T|\) 那么我们不断尝试跳 \(link\) 直到第一个 \(u\) 刚好满足 \(l \ge |T|\) 就可以了。
int version[Maxn];ll Calc(char *str, int num) { ll res = 0; int u = 1, lcs = 0, len = strlen(str + 1), bas = len >> 1; For (i, 1, len) { int id = str[i] - 'a'; if (trans[u][id]) u = trans[u][id], ++ lcs; else { for (; u && !trans[u][id]; u = link[u]) ; if (!u) { u = 1; lcs = 0; } else lcs = maxlen[u] + 1, u = trans[u][id]; } if (lcs >= bas) { while (maxlen[link[u]] >= bas) lcs = maxlen[u = link[u]]; if (version[u] != num) version[u] = num, res += times[u]; } } return res;} 题意
首先认真读题。
给你两个串 \(A,B\) 。然后每天你要和别人博弈,博弈规则如下:
- 一开始你挑选两个串使得它们分别为 \(A,B\) 的一个子串,分别写在两张纸上。
- 你先手。每次轮流在两张纸上其中一张的串尾添加一个字符,使得其仍为这张纸所指的原串 \((A~ or~ B)\) 的一个子串。
- 操作到不能添加就算输。
然后每天你可以制定这两个子串,但任意两天不能重复,字典序从小到大制定(先比 \(A\) 再比 \(B\) )。且你需要一直赢 \(k\) 天,问第 \(k\) 天你给出的字符串是什么。如果无解输出 \(NO\) 。
\((|A|,|B| \le 10^5, k \le 10^{18})\)
题解
我们每次末尾添加一个字符并仍是原串的一个子串的操作就相当于在 \(SAM\) 按照 \(trans\) 移动到后一个节点。然后没有转移了就为败态。由于 \(trans\) 是个 \(DAG\) 图,我们这个相当于在 \(DAG\) 上进行移动,我们可以直接用组合游戏 \((nim)\) 的结论,也就是 \(SG\) 函数。
对于 \(DAG\) 上任意一个点的 \(SG\) 值为 \(mex_{v\in G[u]} \{SG[v]\}\) 。 \(mex \{S\}\) 定义为 \(S\) 集合中第一个未出现的自然数。然后必败态的 \(SG\) 值为 \(0\) 。如果初始状态的 \(SG\) 值不为 \(0\) 先手必胜,否则必败。
然后这是两个独立的游戏,把它们合并的话就是它们所有的 \(SG\) 异或和不为 \(0\) 先手必胜,否则必败。
但此处是要求第 \(k\) 个可行的答案。那么我们只要首先在 \(A\) 的 \(trans\) 上按 \(a \to z\) 的顺序走,每次走的时候只要保证接下来走的对应方案数足够就行了。
那么我们需要统计一个这个东西 \(tot[u][i][0/1]\) 表示 \(u\) 这个状态包含的子串为前缀 \(SG\) 值 是/否 为 \(i\) 的子串个数。
例如对于 \(\underline{ab}\) 来说,状态 \(1\) 为起点,它包含的子串为 \(\underline{}\) (空串)。所以它为前缀所包含的子串集合为 \(\{\underline{}, \underline{a}, \underline{b}, \underline{ab}\}\) 。\(SG\) 值分别为 \(\{2,1,0,0\}\) 所以它的 \(tot[1][2][1]=1,tot[1][2][0]=3\) 。
这个 \(tot\) 与 \(SG\) 可以直接先求出 \(trans\) 的拓扑序,然后倒推就行了,这个比较容易推。然后我们有了这个就很好做了。
不难发现 \(SG\) 值最多只有 \(26\) 因为每个点最多只会有 \(26\) 个出边,所以这些最多只能从 \([0,25]\) 取值,也就是说这个点 \(SG\) 值最大为 \(26\) 。
我们首先确定 \(A\) 的串应该是什么,我们从高到低依次枚举每一位,判断是否在需要走入其中。具体来说我们假设当前到了 \(SAM\) 的第 \(u\) 个点需要取字典序第 \(k\) 小的字符串,在当前这个点的结束条件是 \(B.tot[A.SG[u]][S][0] \le k\) 也就是意味着对于这个点能取胜的总方案数是 \(B\) 中 \(SG\) 不和 \(A.SG[u]\) 相等的子串数。然后如果在当前节点结束不了,那么我们先减去这一部分的贡献。然后枚举接下来那一位,选择这个节点的贡献就是 \(\displaystyle \sum_{i=0}^{c+1} A.tot[v][i][1] \times B.tot[1][i][0]\) 也是就走完这一步后手必败的方案数之和,然后判一下大小就行了。
接下来只需要确定 \(B\) 串了,我们只需要用之前最后确定 \(A\) 串的 \(SG\) 函数去算就行了,具体见代码。(似乎写的有点长。。。凑合看吧。。。)
时间复杂度 \(O((|A|+|B|)c)\) ,\(c\) 为字符集大小。
#include#define For(i, l, r) for(register int i = (l), i##end = (int)(r); i <= i##end; ++i)#define Fordown(i, r, l) for(register int i = (r), i##end = (int)(l); i >= i##end; --i)#define Set(a, v) memset(a, v, sizeof(a))#define Cpy(a, b) memcpy(a, b, sizeof(a))#define debug(x) cout << #x << ": " << x << endlusing namespace std;inline bool chkmin(int &a, int b) {return b < a ? a = b, 1 : 0;}inline bool chkmax(int &a, int b) {return b > a ? a = b, 1 : 0;}typedef long long ll;inline ll read() { ll x = 0, fh = 1; char ch = getchar(); for (; !isdigit(ch); ch = getchar()) if (ch == '-') fh = -1; for (; isdigit(ch); ch = getchar()) x = (x << 1) + (x << 3) + (ch ^ 48); return x * fh;}void File() {#ifdef zjp_shadow freopen ("1466.in", "r", stdin); freopen ("1466.out", "w", stdout);#endif}const int N = 1e5 + 1e3, Maxn = N << 1, spc = 25;struct Suffix_Automata { int trans[Maxn][spc + 1], maxlen[Maxn], minlen[Maxn], link[Maxn], Size, Last; Suffix_Automata() { Last = Size = 1; } inline void Extend(int id) { int cur = (++ Size), p; maxlen[cur] = maxlen[Last] + 1; for (p = Last; p && !trans[p][id]; p = link[p]) trans[p][id] = cur; if (!p) link[cur] = 1; else { int q = trans[p][id]; if (maxlen[q] == maxlen[p] + 1) link[cur] = q; else { int clone = (++ Size); maxlen[clone] = maxlen[p] + 1; Cpy(trans[clone], trans[q]); link[clone] = link[q]; for (; p && trans[p][id] == q; p = link[p]) trans[p][id] = clone; link[cur] = link[q] = clone; } } Last = cur; } int SG[Maxn], lis[Maxn], indeg[Maxn], cnt; ll tot[Maxn][spc + 2][2]; void Get_SG_Tot() { queue Q; cnt = 0; Q.push(1); For (i, 1, Size) For (j, 0, spc) if (trans[i][j]) ++ indeg[trans[i][j]]; while (!Q.empty()) { int u; u = lis[++ cnt] = Q.front(); Q.pop(); For (i, 0, spc) { int v = trans[u][i]; if (!v) continue ; if (!(--indeg[v])) Q.push(v); } } bitset App; Fordown (i, cnt, 1) { int u = lis[i]; App.reset(); For (j, 0, spc) { register int v = trans[u][j]; if (v) { App[SG[v]] = true; For (k, 0, spc + 1) tot[u][k][1] += tot[v][k][1]; } } for (int j = 0; ; ++ j) if (!App[j]) { SG[u] = j; break; } ll sum = 0; ++ tot[u][SG[u]][1]; For (i, 0, spc + 1) sum += tot[u][i][1]; For (i, 0, spc + 1) tot[u][i][0] = sum - tot[u][i][1]; } } void Out() { For (i, 1, Size) { debug(i); For (j, 0, 5) printf ("%lld%c", tot[i][j][1], j == jend ? '\n' : ' '); debug(SG[i]); } }} A, B;char ansa[N], ansb[N];ll k;int Get_A(int u, int cur) { ll cnt = B.tot[1][A.SG[u]][0]; if (k <= cnt) return u; k -= cnt; For (i, 0, spc) { int v = A.trans[u][i]; if (!v) continue ; ll now = 0; For (i, 0, spc + 1) now += 1ll * A.tot[v][i][1] * B.tot[1][i][0]; if (now < k) k -= now; else { ansa[cur] = i + 'a'; return Get_A(v, cur + 1); } } return 0;}void Get_B(int u, int cur, int val) { k -= (val != B.SG[u]); if (!k) return ; For (i, 0, spc) { int v = B.trans[u][i]; if (!v) continue ; ll now = B.tot[v][val][0]; if (now < k) k -= now; else { ansb[cur] = i + 'a'; Get_B(v, cur + 1, val); return ; } }}char str[N];int main () { File(); k = read(); scanf ("%s", str + 1); For (i, 1, strlen(str + 1)) A.Extend(str[i] - 'a'); A.Get_SG_Tot(); A.Out(); scanf ("%s", str + 1); For (i, 1, strlen(str + 1)) B.Extend(str[i] - 'a'); B.Get_SG_Tot(); int pos = Get_A(1, 1); if (!pos) return puts("NO"), 0; Get_B(1, 1, A.SG[pos]); printf ("%s\n", ansa + 1); printf ("%s\n", ansb + 1); return 0;}